Project information
- Category: Big Data Skillset
- Description: Final Exam Course
- Project date: December, 2022
- Project URL: Github
Design data schema and analyze knowledge discovery in database (KDD) of Academic System Simaster UGM
Simaster UGM is student academic system of Universitas Gadjah Mada.
Big Data Skillset:- Analyze business process and data requirements.
- Design database star schema.
- Perform data mining to knowledge discovery.
- Analyze business process and data requirements
- Design database schema
- Perform data mining to knowledge discovery
Simaster UGM menu display
Business Process:
Graduates of university have a social and intellectual responsibility to become a member of society who has the high competencies include hard skill and soft skill. Therefore, a university needs to help graduates in good career planning. Simaster UGM has Academic Affairs and Career Alumni menu which really support their students in career planning. The process chosen in designing the star database schema is the career planning process. The design carried out will represent the Symphony sub menu, with needed additional data such as study results data.
Data Requirements
Profile menu: Name, NIM, Study Program, Level and Class.
Study results submenu: Semester and year period, course code, courses, credits, and value.
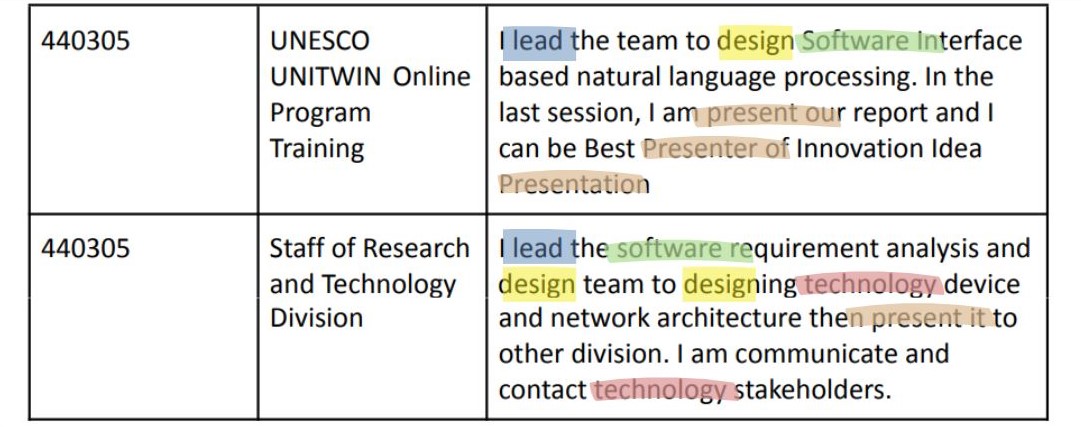
Curriculum Vitae submenu: ID number, name of experience such as the name of the training attended, experience of the internship position, then
explanatory description and time period of the experience.
Tools: Draw.io
The grain of the fact table is student activities inside and outside lectures.
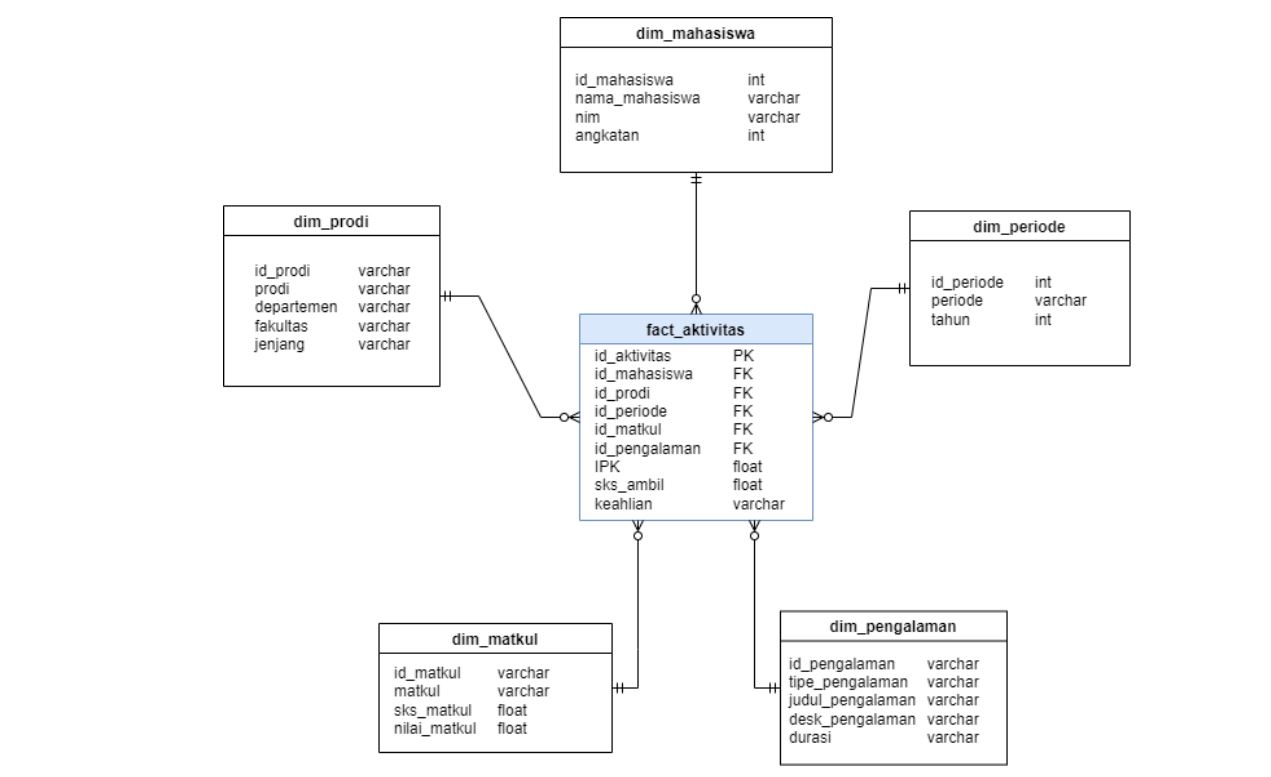
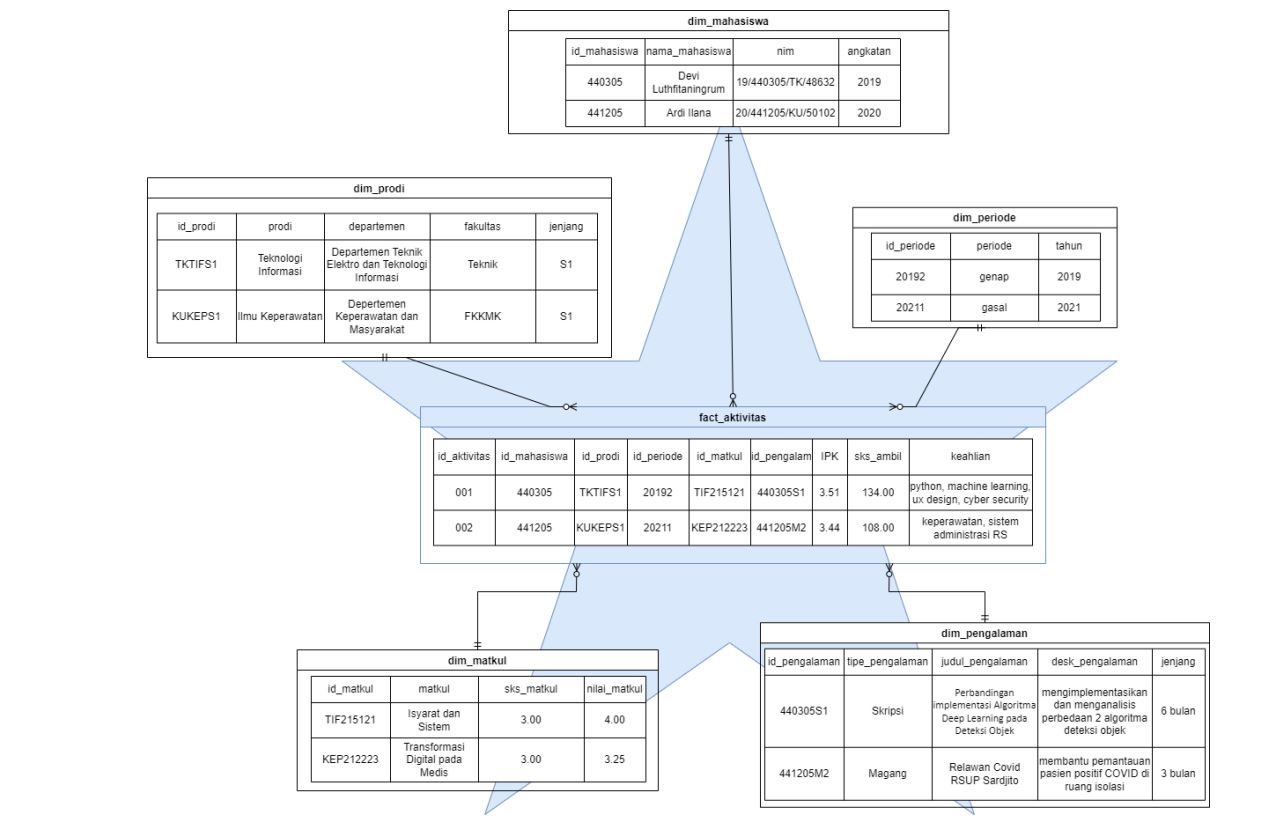
Tools: SQL, Python, Big Data tools (Apache, etc)
Classification of student's CGPA prediction
SELECT id_mahasiswa as “NIU”, nama_mahasiswa as “Nama”, nilai_matkul as “nilai”,
sks_matkul as “sks”, nilai*sks as “total_nilai
FROM fact_aktivitas, dim_mahasiswa, dim_matkul
GROUP BY(NIU)
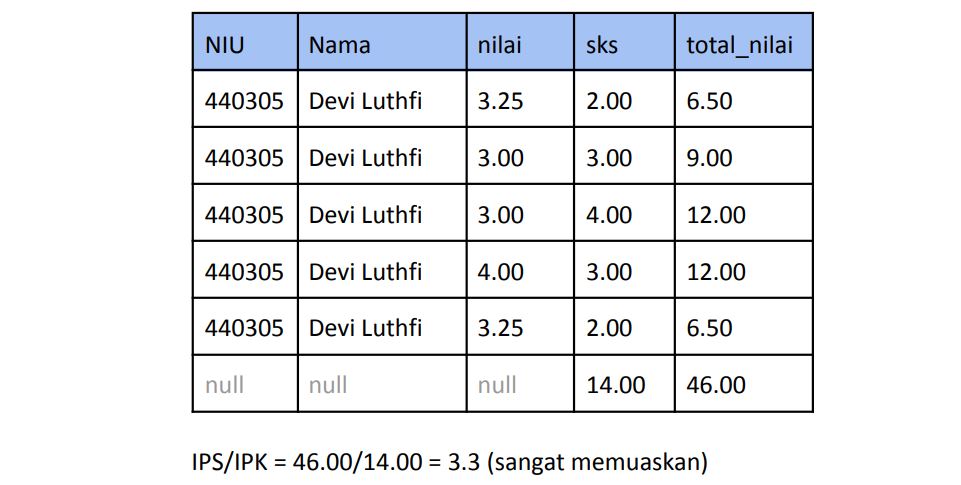
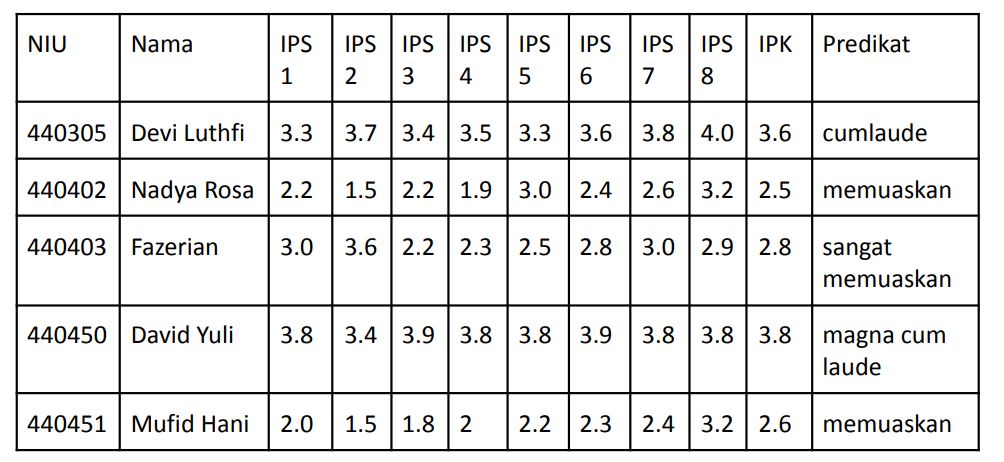
Predictions are carried out at the end of each semester to forecast the CGPA. The forecast will help students in preparing strategy for achieving the desired CGPA target. So students will be motivated to improve grades in the next semester.
Clustering of career path course
SELECT id_matkul, COUNT(id_mahasiswa) as “jumlah_peserta”
FROM fact_aktivitas
GROUP BY (id_matkul)
The algorithm commonly used for clustering is the K-Means algorithm.
This algorithm begins by determining the desired number of clusters
existing datasets. In this experiment, the value k=3 was determined, it would form
3 clusters, C1, C2, and C3. Grouping based on course variables
unfavorite, moderate, and favorite.
The initial centroid is determined randomly, example C1=12 students, C2=30 students, and C3=80 students. Then, using the Euclidean Distance formula, the distance between the data and the centroid is calculated.
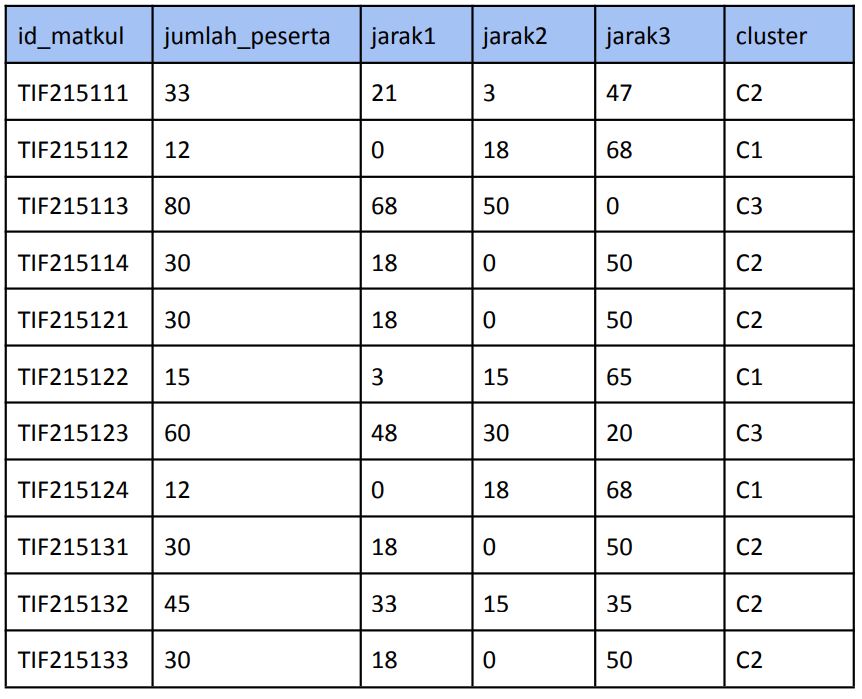
Clustering of first iteration
unfavorite: TIF215112, TIF215122, TIF215124, TIF215134.
moderate: TIF215111, TIF215114, TIF215121, TIF215131, TIF215132, TIF215133
favorite: TIF215113, TIF215123
Forecast of GPA
SELECT id_mahasiswa as “NIU”, nilai_matkul as “nilai”, sks_matkul as “sks”, nilai*sks
as “total_nilai
FROM fact_aktivitas, dim_matkul
WHERE id_mahasiswa=440305 AND id_periode=20191
GROUP BY(NIU)
The CGPA score cannot be increased instantly, but a stable and satisfactory GPA score is needed every semester. GPA is a variable
response to time with semester periods so that it can be forecasted
with time series forecast. The GPA score should not be
forms a trend but changes occur smoothly, then the method
The appropriate method is the exponential smoothing method. On exponential
smoothing, the values used to forecast GPA for the next semester are the previous GPA and forecast. This can minimize other influencing factors
GPA in a certain period (outliers are formed) in the forecast calculation. GPA value
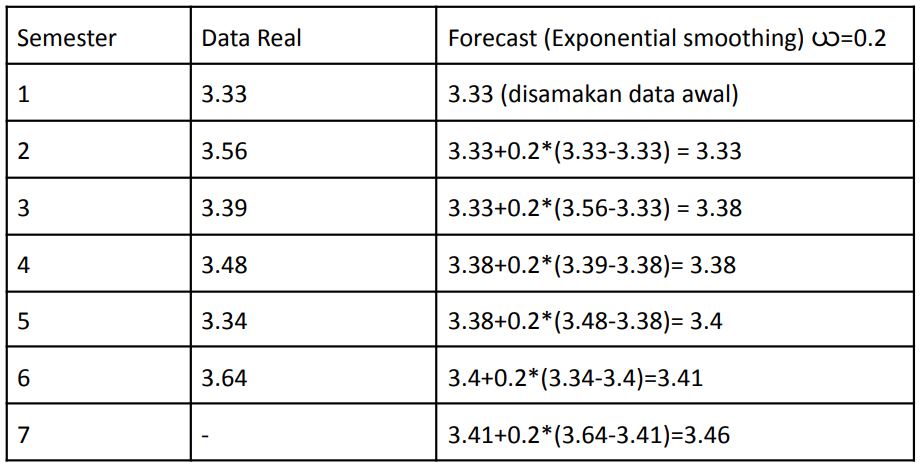
The past period is given a weight ယ where 0 ≤ယ≤1.
Forecast (t) = Forecast (t-1) + ယ*{Actual(t-1)-Forecast(t-1)}
The following is an example of a forecast calculation with a weight of ယ=0.2:
Association rule of course
SELECT id_mahasiswa as “NIU”, id_matkul
FROM fact_aktivitas
GROUP BY (id_mahasiswa)
To execute the association rule, the course taken by each student needs to be converted into cross-tabulated:
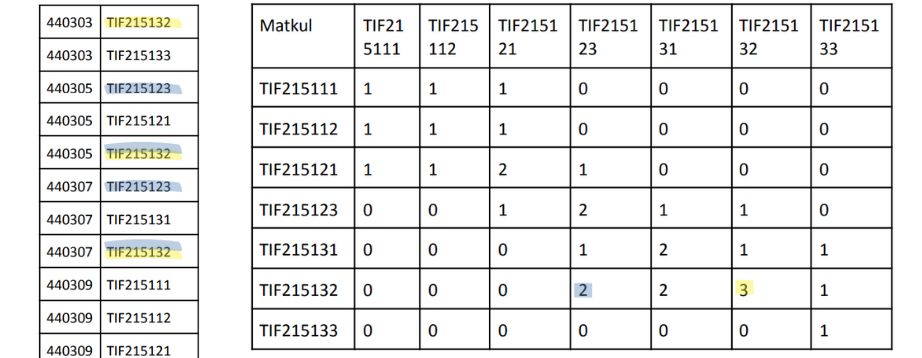
Many students take course TIF215123 and TIF215132 simultaneously, while course that taken by almost all students is the TIF215132 course.
Text mining of student skills
judul_pengalaman dan desk_pengalaman can be used for text mining. Text mining can be done to look for skills or expertise
that students have based on experience such as internships, projects, research, etc.
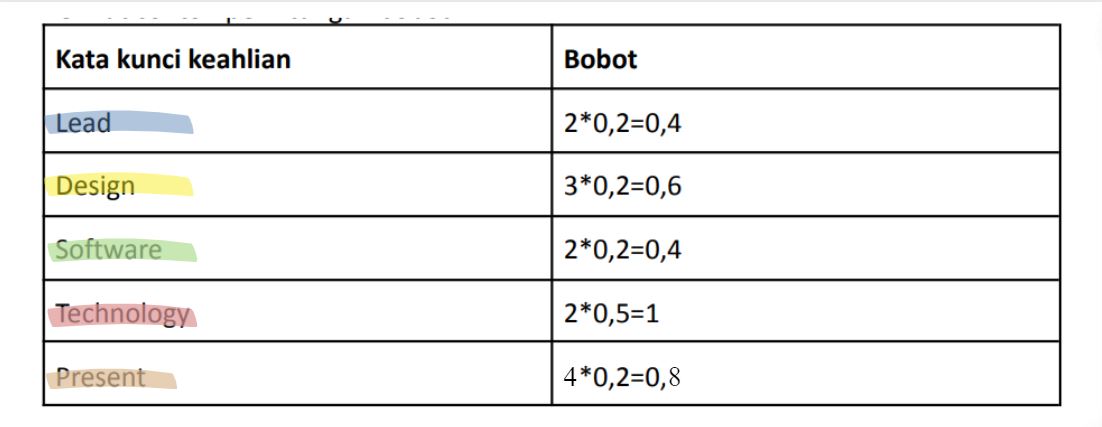
The Term Frequency-Inverse Document Frequency (TF-IDF) method is a way of giving weight to the relationship of a word (term) to a document. This method combines 2 concepts of weight calculation, The expertise term often appears in titles or descriptions of student experiences become the student's expertise. Meanwhile, the expertise term in many other people experience will have little weight. So, the weight of each word is:
ယ= TF*IDF